The AWS Managed Policies Trap

These policies are simultaneously appealing and dangerous. Here’s how to use automated analysis of environment configuration and activity logs to avoid getting caught in the trap.
Amazon Web Services (AWS) managed policies are a widely used feature of AWS Identity and Access Management (IAM) which enables out-of-the-box access to AWS resources. Even though this feature has long been considered a security weakness, it is still very popular.
This post explains why these policies are simultaneously very appealing and dangerous to use. We will examine what causes the “AWS managed policies trap” and how to escape it using automated analysis of environment configuration and activity logs.
AWS managed policies: What are they good for?
AWS managed policies are IAM policies that are maintained and controlled by Amazon. You can view changes made to them and the current “default” (i.e. operative) version of the policy in the “policy versions” tab. You may assign them to principals providing a predefined set of permissions deemed fit for the function that the principal is supposed to perform by Amazon. This article shares examples of AWS-managed policies for different job functions.
Using these policies is detrimental to the practice of achieving least privilege in an environment. Before demonstrating this point, let’s take a look at the philosophy behind them so we can understand where (and, more importantly, when) they are meant to be used. This will help us understand the “AWS managed policies trap,” so we can avoid it.
Managing permissions through IAM policies can get pretty complicated. That being said, IAM is also one of the most fundamental AWS services. It’s actually hard to think of an AWS service you can use properly without configuring an IAM policy. This combination is what makes the existence of AWS managed policies a necessary evil.
When using an AWS service for the first time, you grant principals permission to access it. However, for several reasons, performing this task can be pretty difficult because you don’t know which permissions are required, or the person who will use the service doesn’t know what permissions they need either. This could be true both for a human (e.g. a developer) or a machine (e.g. an Elastic Compute Cloud [EC2] instance).
This is exactly why it’s very helpful, if not indispensable, to have a go-to answer, based on very common use cases, for the question “Which permissions are required for this principal to do its job?” Think back to when you first learned to ride a bicycle. If you’re like most people, you used training wheels. You can look at AWS managed policies the same way — they’re the training wheels to get you up and running using your AWS environment. This narrative can actually be found in the AWS documentation about IAM best practices:
“Providing your employees with only the permissions they need requires time and detailed knowledge of IAM policies. Employees need time to learn which AWS services they want or need to use. Administrators need time to learn about and test IAM.
“To get started quickly, you can use AWS managed policies to give your employees the permissions they need to get started.”
The thing about training wheels, though, is that even though they’re extremely important when you’re starting out, if you keep using them past a certain point, they will probably do more harm than good. While real-life bicycle training wheels might not be a security risk, AWS Managed Policies probably will be. Let’s find out why.
A security risk in more than one way
By definition, the concept of an AWS managed policy contradicts the principle of least privilege; instead of creating a perfect fit that enables a specific entity to do its job, you use a “one-size-fits-all” policy.
There are several reasons why using such a policy long-term can be risky. Let’s explore some of them.
Too many permissions
Simply put, a policy that wasn’t designed for a specific entity in a specific organization can’t, almost by definition, function properly without granting broad permissions.
In a recent analysis of configuration and activity within a sample of our clients’ cloud environments, we found that a staggering 66% percent of the permissions assigned to principals using AWS-managed policies were never used. At all. That is, two out of every three permissions weren’t necessary for the organization to function. If a principal assigned an AWS-managed policy got compromised, most of the permissions the attackers would gain access to were never necessary. That’s incredible.
The name of the AWS policy usually provides some insight into what it allows. However, some occurrences of AWS-managed policies provide extreme privileges you wouldn’t necessarily expect, making them more susceptible to abuse. We’d like to point out a few of them.
In its current version (2), the policy AmazonConnectFullAccess allows kms:CreateGrant permissions to “*”. Keep in mind, kms:CreateGrant is an extremely sensitive action which can be used to grant any principal (including of course, the principal to which it’s assigned) permission to perform any action possible on a KMS CMK, including kms:Decrypt if it’s applicable. This means that a principal with this policy assigned to it, unless otherwise restricted, would be able to access all the sensitive information encrypted by any customer-managed key in the account, for example. We can assume that managing an Amazon Connect instance requires delegating the use of various client-managed KMS keys, and it’s not possible for an AWS-managed policy to know which they are (since they are customer-managed), but this type of over-provisioning is outrageous.
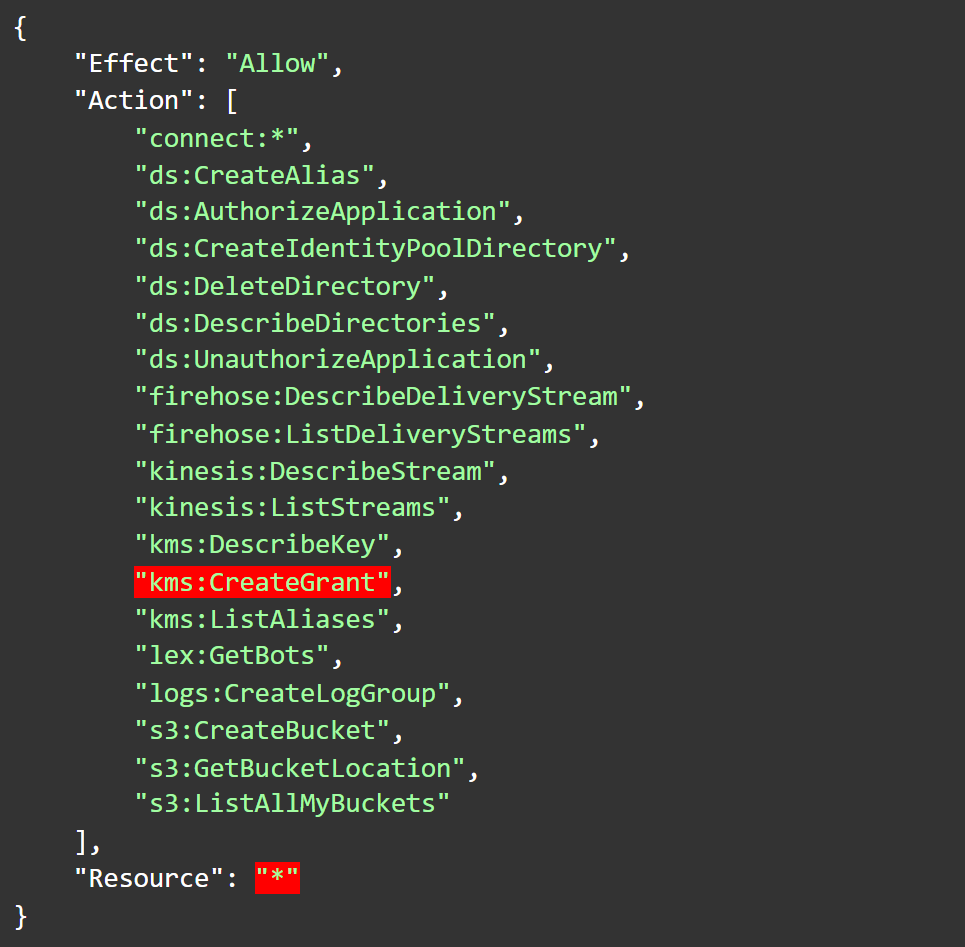
Figure 1: Statement from version 2 of AmazonConnectFullAccess allowing kms:CreateGrant on “*”
Image source: Tenable screengrab from AWS
This could also happen for policies designed for specific job functions. The DataScientist policy in its current version (5) provides full access (not just read / query) to many types of data services (e.g. RDS, SDB, Redshift and DynamoDB) along with access to Amazon Simple Storage Service (S3) - Get*, List* and DeleteObject. It can also terminate all EC2 instances. Imagine a data scientist using credentials with programmatic access utilizing an access key and secret on their workstation ... and that workstation is somehow compromised. There is no reason the attacker should be able to gain full access to ALL of these data services and be able to terminate ALL the EC2 activity on the account.
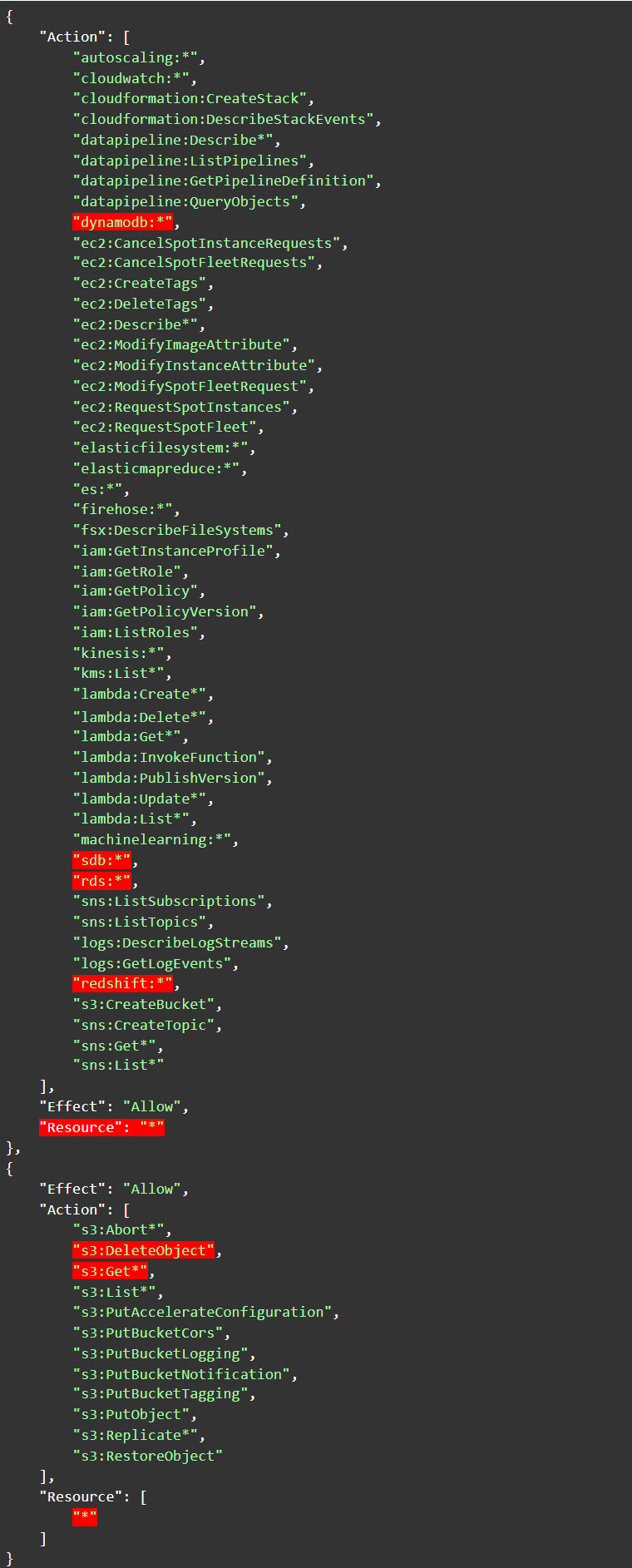
Figure 2: Statements from version 5 of the DataScientist policy
Image source: Tenable screengrab from AWS
The implications of what can be done with a policy are not always clear even if you review them. For example, AWSElasticBeanstalkFullAccess in its current version (8) has a combination of permissions which is toxic if you think two or three steps ahead. That policy has an Allow for “ec2:*” and “elasticbeanstalk:*” for “*” while also having an Allow for “iam:PassRole” for “*”.
Figure 3: Statements from version 8 of AWSElasticBeanstalkFullAccess
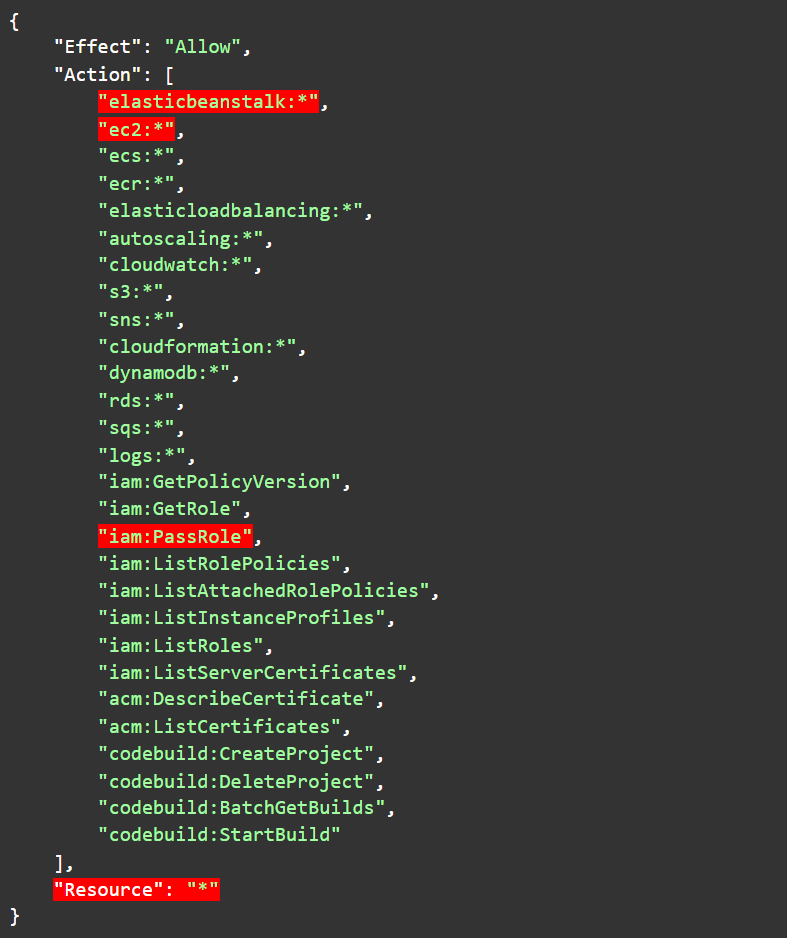
Image source; Tenable screengrab from AWS
This combination means a principal wielding this policy, unless otherwise restricted, could execute code on any EC2 or ElasticBeanstalk environment while passing any role to it. In other words, the principal can actively use any role that has any EC2 instance or an Elastic Beanstalk environment in their trust policy. This is probably a little bit more than what most admins using this policy would bargain for when assigning it.
AWS has the control
Another reason using an AWS-managed policy is a bad habit is that you willingly relinquish control over the policy assigned to the principal.
Amazon is a terrific company and it can be assumed that it put a lot of thought and effort into configuring these policies. However, it may still take a policy you once believed was configured well for your use case and change it in a way that isn’t. This can happen even without you even knowing.
In addition, just like any other company, Amazon can make mistakes. We got a reminder of that just a few weeks ago when version 69 of ReadOnlyAccess was deployed and included some statements which are clearly not read only, including this one:
Figure 4: Statement from version 69 of ReadOnlyAccess allowing full access to Cassandra

Image source: Tenable screengrab from AWS
It allows full (!) access to all Cassandra resources. It’s hard to believe this was done on purpose. Amazon should be commended for catching it almost immediately; version 70 was deployed a short four minutes after its predecessor. It’s not clear how long, if at all, version 69 was the default version, but it’s easy to imagine what kind of damage could have been done had things turned out differently. In fact, at the time of writing this article, version 68, which preceded this version, is configured as the default for the policy even though versions 70 and 71 have been deployed. You can understand why.
Figure 5: Policy versions of ReadOnlyAccess (taken on 15/11/2020)
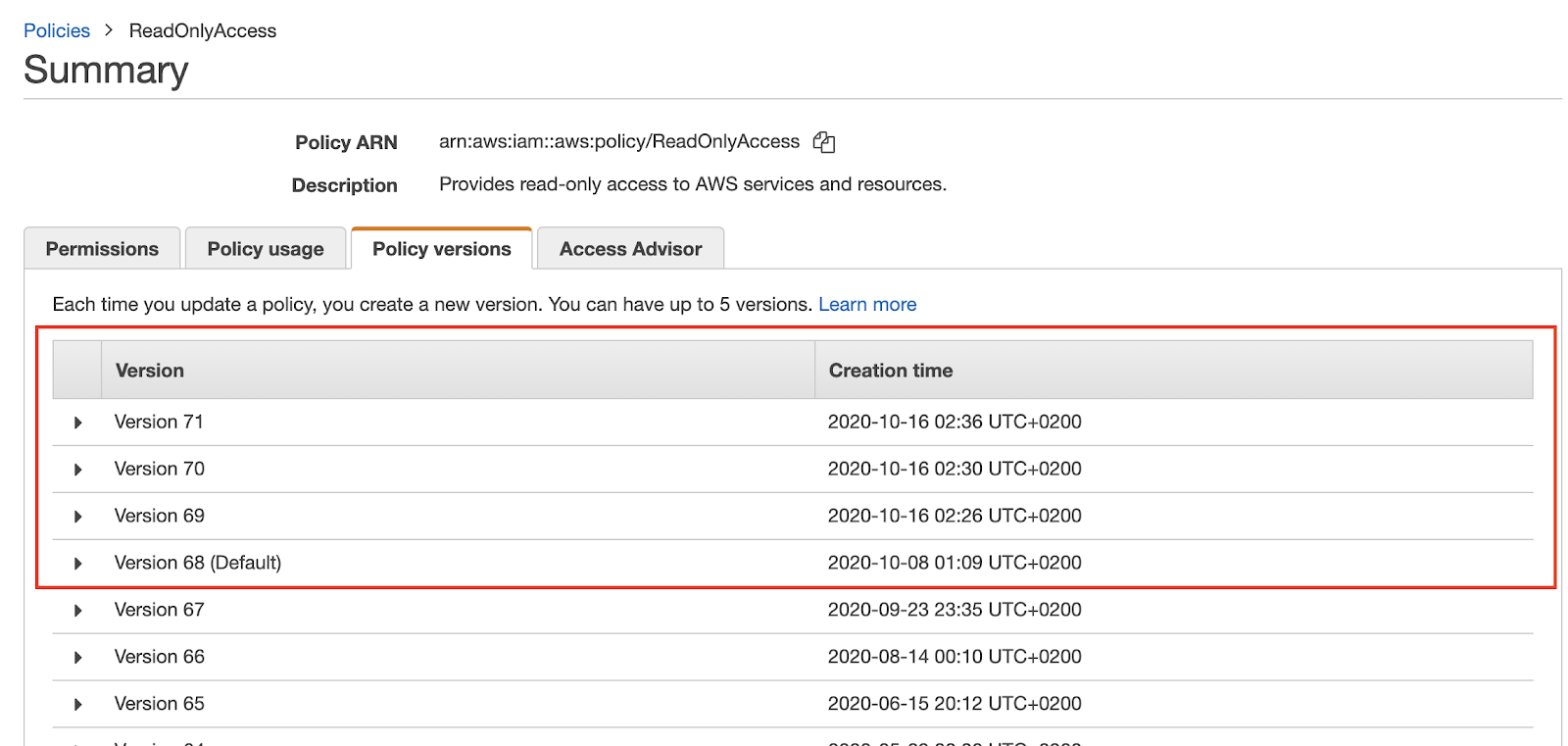
Image source: Tenable screengrab from AWS
Policies can NOT be granular. At all.
One of the worst limitations of an AWS managed policy is that it’s over privileged by design; it is impossible to granularly assign permissions based on business requirements. Actions allowed via AWS managed policies can’t be limited to a specific resource or group of resources chosen by you. Rarely does a user need access to ALL resources of the same type — even administrators. Similarly, it’s bad practice to allow a machine to access all resources of a certain type.
This is true even if the actions allowed on the resource are limited. For example, a policy such as AWSLambdaReadOnlyAccess might sound innocent enough to use on your Lambda function which requires access to data resources. But why would any Lambda function require the ability to list and download (s3:List* and s3:Get*) ALL objects in ANY of the S3 buckets in your environment (as currently allowed in version 8)?
Figure 6: Statement from version 8 of AWSLambdaReadOnlyAccess
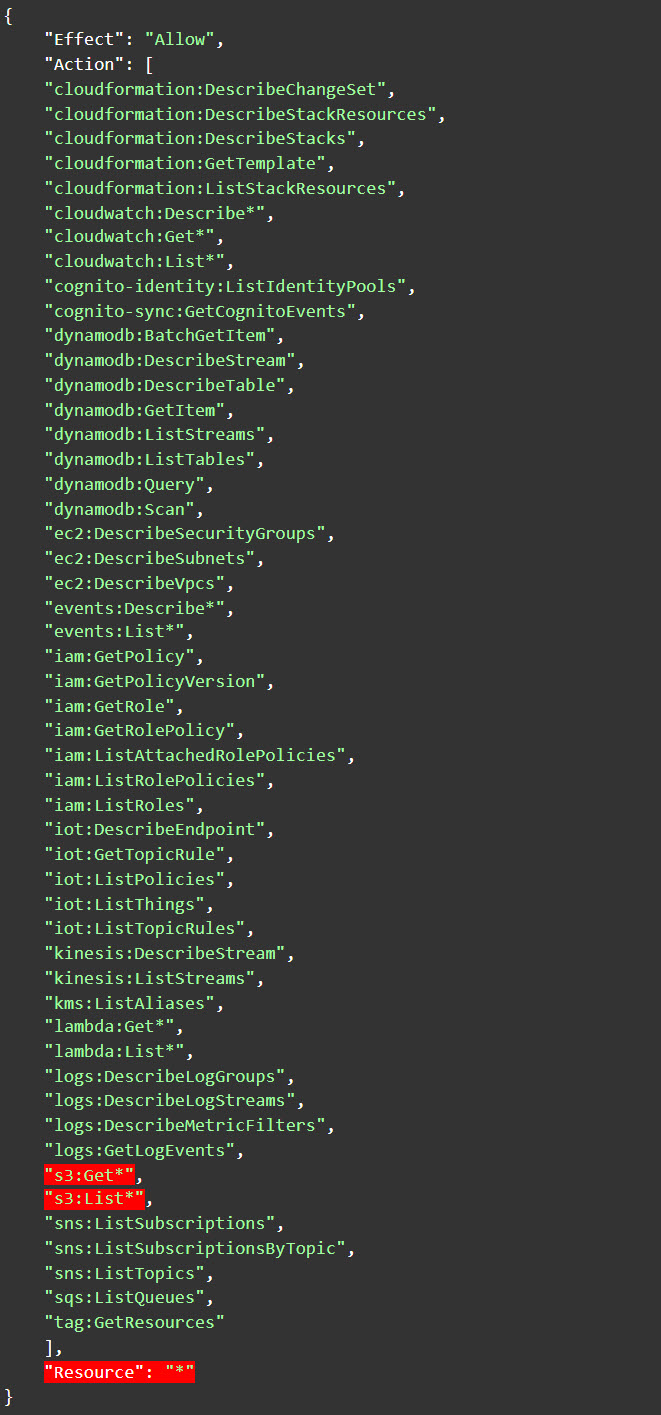
Image source: Tenable screengrab from AWS
The AWS managed policies trap
Pressure from internal stakeholders compels most system administrators to “hit the ground running,” rather than focus on security, when spinning up cloud infrastructure. These “quick fixes” can have lasting consequences, especially if they are the cause of a security breach. Using AWS managed policies is a very unfortunate example of this fact of life.
As we mentioned before, when starting out, it’s nearly impossible to configure the exact policy that is needed. This is why, as a “temporary” solution, most environment administrators simply apply the AWS managed policy they deem most fitting to each use case and move on. However, this ”temporary” solution very quickly becomes permanent. Unfortunately, the cost of building custom policies grows over time as the network and permissions model becomes increasingly complex. And, let’s be honest here, as long as everything functions properly and no alarms go off, does it matter whether you are using an AWS managed policy?
The simple answer is yes. When (notice this is not a matter of “if,” but “when”) a breach occurs, excessive permissions can make the business damage that much greater. Let’s have a look at an example.
The exposed S3 bucket
Let’s say you have an external-facing EC2 instance that serves an application to a wide range of external addresses. Let’s assume this EC2 instance also has to use S3 buckets for operational reasons; it reads data files and configurations from one and it writes logs to another. When configuring this EC2 instance, the network administrator finds it difficult to determine all the buckets to which it would need access and provides it with the AWSS3FullAccess policy.
This, of course, is a terrible idea. However, if done in a staging environment for the purpose of adjusting the buckets the application works with and then, when going into production the permission gets replaced with a “right-sized” one, there’s little to no harm. If the policy assignment is reproduced in production and remains as is, really bad things could happen.
Obviously, you trust the application served on the EC2 and the code it runs; however, software is prone to flaws and vulnerabilities. When the EC2 is internet-facing, a malicious actor can potentially leverage a vulnerability to gain control of the machine. In this case, having the wrong policy could be incredibly significant. If, for example, one of the buckets contains sensitive information, it could be leaked or tampered with. If a little more thought had been put into assigning permissions, the fallout from such a breach could have been reduced dramatically.
The case for automated analysis
If it is so important to right-size permissions assigned to principals, why is it not the common practice? In other words, how did we get to the point where we have to write this post?
Because unfortunately this task is very hard to do well and also very risky if you do it wrong.
When building an environment, it’s extremely hard to track the policies that were assigned and to determine which resources need access to perform which actions on which assets. If, theoretically, application development practices included more rigorous documentation and processes were put into place to approve and track permissions granted to applications and / or people, it may have been easier. But it’s not realistic for most organizations..
On the flip side, it’s also problematic to make mistakes while trying to build granular, least-privilege policies. If IAM limitations prevent applications or people from performing tasks they need to do, it can cause a Denial of Service, which can be as damaging as a breach.
Fortunately, there are automated solutions like Tenable Cloud Security that provide the analytics necessary to solve this problem. With Tenable, you can right-size cloud resource permissions with greater ease and confidence to make your environment much more secure.
Let’s see how a scenario like the one above would play out after connecting to the Tenable platform.
Once Tenable Cloud Security analyzes the configuration and log activity in the environment, it would alert about the risk of excessive permissions granted to the role assigned to the EC2 as there are clearly buckets it doesn’t access.
Figure 7: List of risks of excessive permissions. The first (in the red frame) indicates the excessive permissions originating from the AmazonS3FullAccess policy
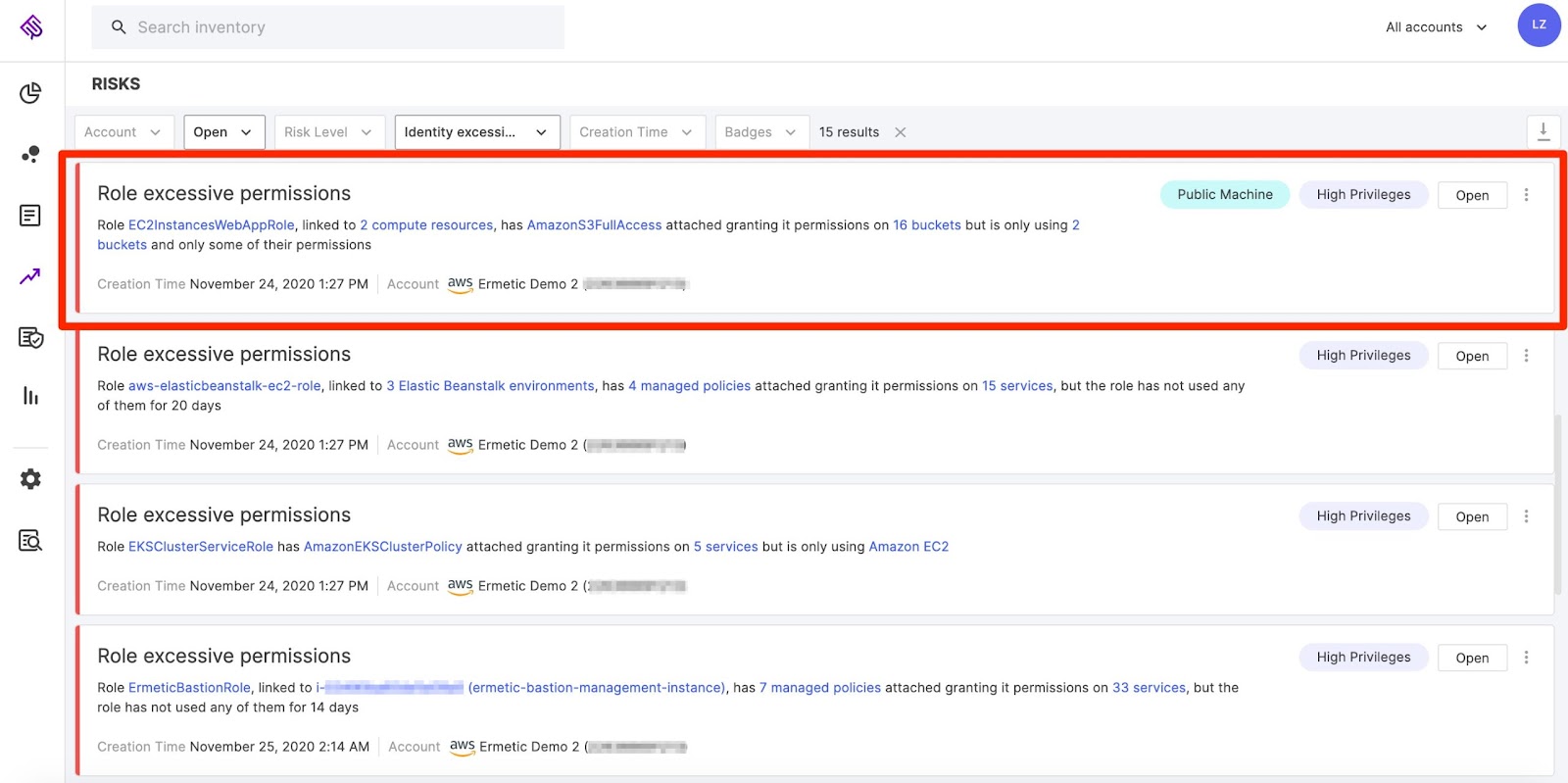
Image source: Tenable
Looking closely at the risk. It states that the role is linked to two compute resources, and we can also list them, as shown in Figure 8:
Figure 8: Listing the compute resources linked to a role which is the subject of a risk. The risk also indicates one of the machines is public.

Image source: Tenable
Another thing we can see in Figure 8 is that one of the compute resources the risk applies to is public and merits a closer look. If we navigate to the page of the EC2 instance listed here and go to its network tab, we can see this machine is, in fact, exposed to the internet which makes it clear this is a crucial issue to fix.
Figure 9: Network graph from Tenable Cloud Security displaying the EC2 at risk to being exposed to the internet
Image source: Tenable
Going back to the risk list, we can navigate to the dedicated risk page, which has more information about the risk and the role it originates from:
Figure 10: More detailed information about the risk
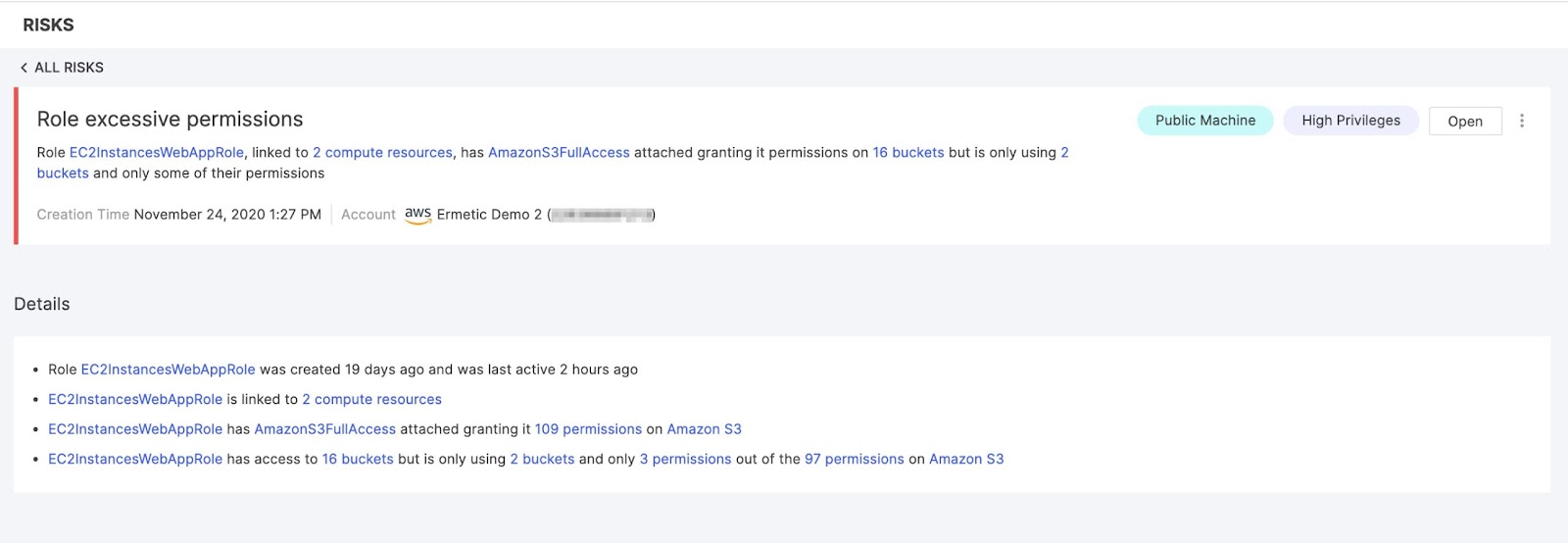
Image source: Tenable
Figure 10 displays the top of the risk page, which shows that while the role has access to 16 buckets and 97 permissions (for different actions, that is) on S3, it only uses two buckets and three of those permissions. This makes a lot of sense considering its origins.
However, this is not the coolest part about the risk page Tenable displays. Using precise analysis of the activity logs, Tenable can tell exactly what permissions are required, so it can suggest a way for you to remediate the risk. Since Tenable analyzes the activity logs (including tests being run on the application for QA reasons) for a prolonged period of time, you can be certain that it’s familiar with the needs of the application and the EC2 it’s hosted on, and will therefore not create a Denial of Service.
The solution for remediating the risk can be found on the remediation panel at the bottom part of the risk screen:
Figure 11: The remediation panel listing the steps for mitigating the risk
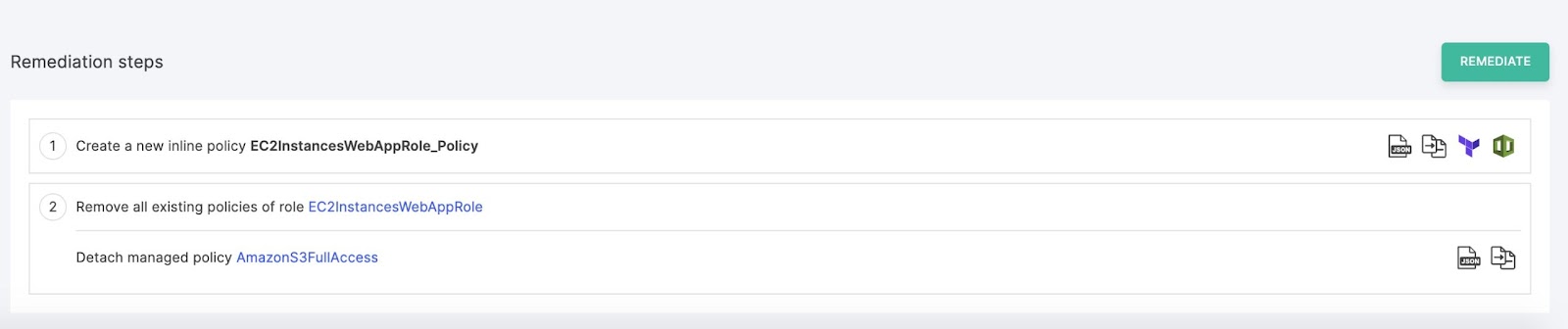
Image source: Tenable
Look closely at the panel displayed in Figure 11 to understand just how powerful it is.
The first step instructs you to create a new inline policy (replacing the AmazonS3FullAccess policy which you are instructed to remove in the next step). On the right side, function buttons make it incredibly easy to implement. You can see the policy in json form to manually apply it via the AWS console:
Figure 12: The json for the Inline Policy suggested to replace AmazonS3FullAccess
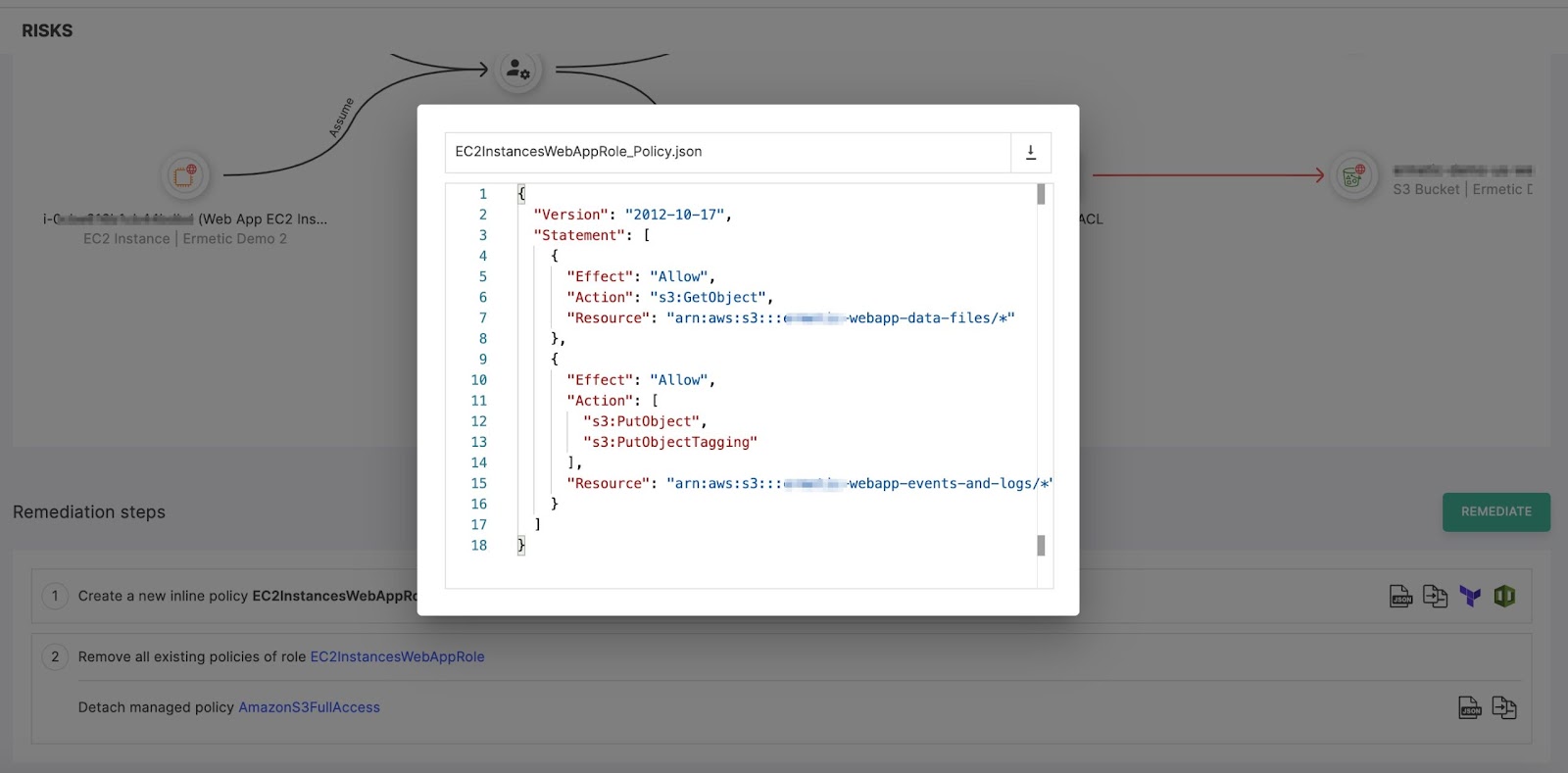
Image source: Tenable
You can also examine the difference between the current policy and the new one you are about to place:
Figure 13: The difference between the existing policy and the new one suggested to replace it
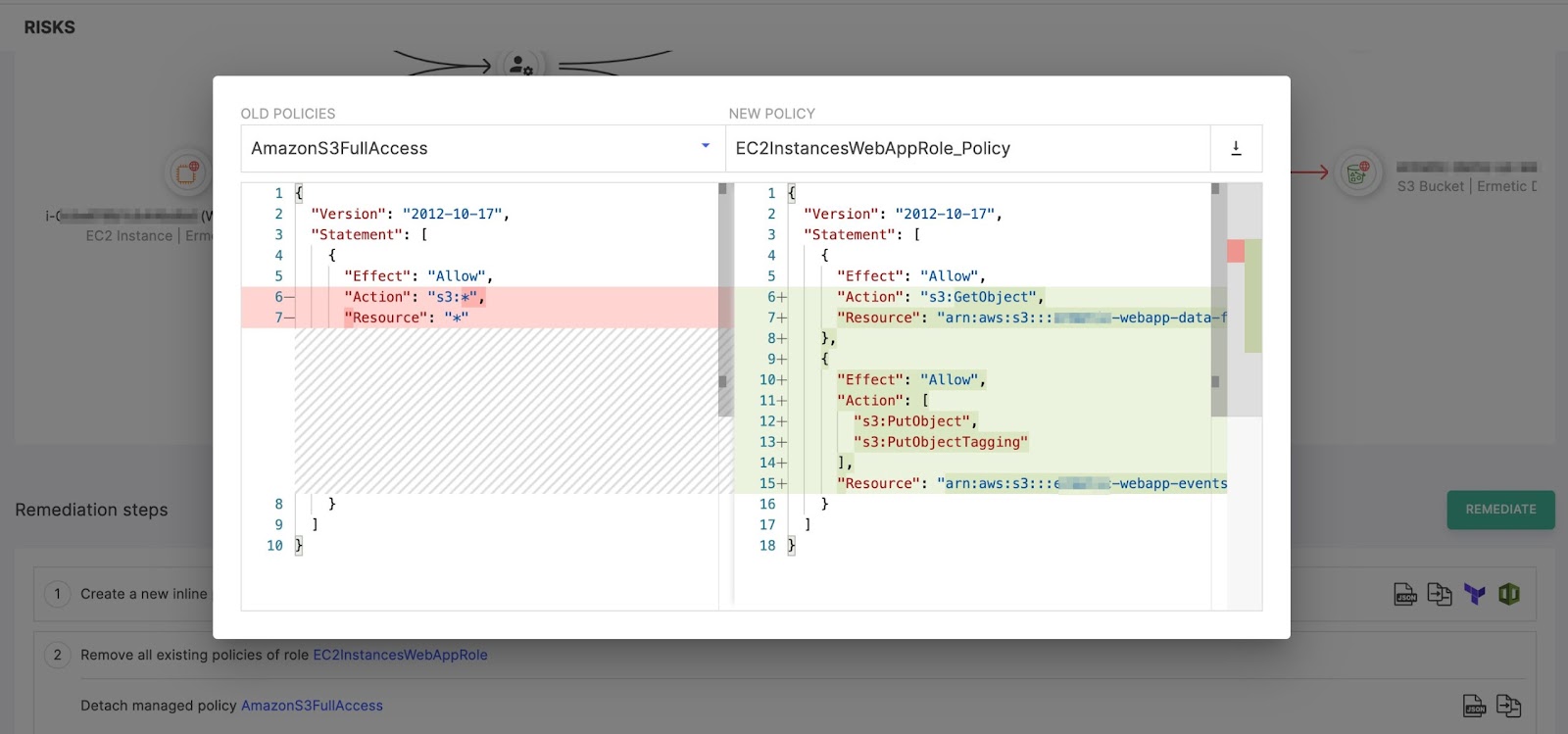
Image source: Tenable
To perform the action using code, you can get a Terraform or CloudFormation script to apply it:
Figure 14: Terraform script ready to use for applying the suggested inline policy
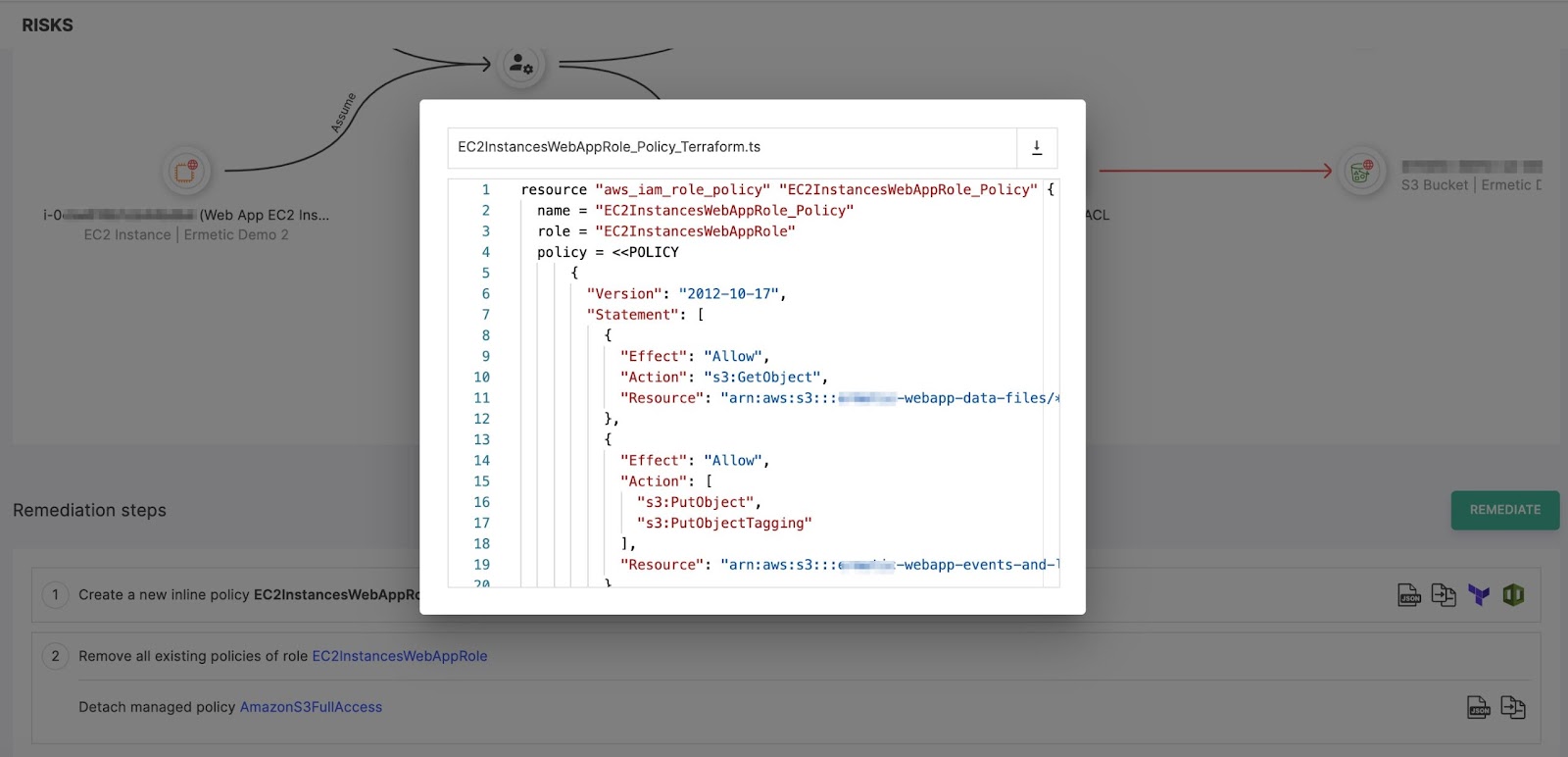
Image source: Tenable
Finally, to perform the suggested remediation straight out of the Tenable console, use the remediation wizard:
Figure 15: The Remediation Wizard allows you to perform the required steps for remediation from the Tenable console
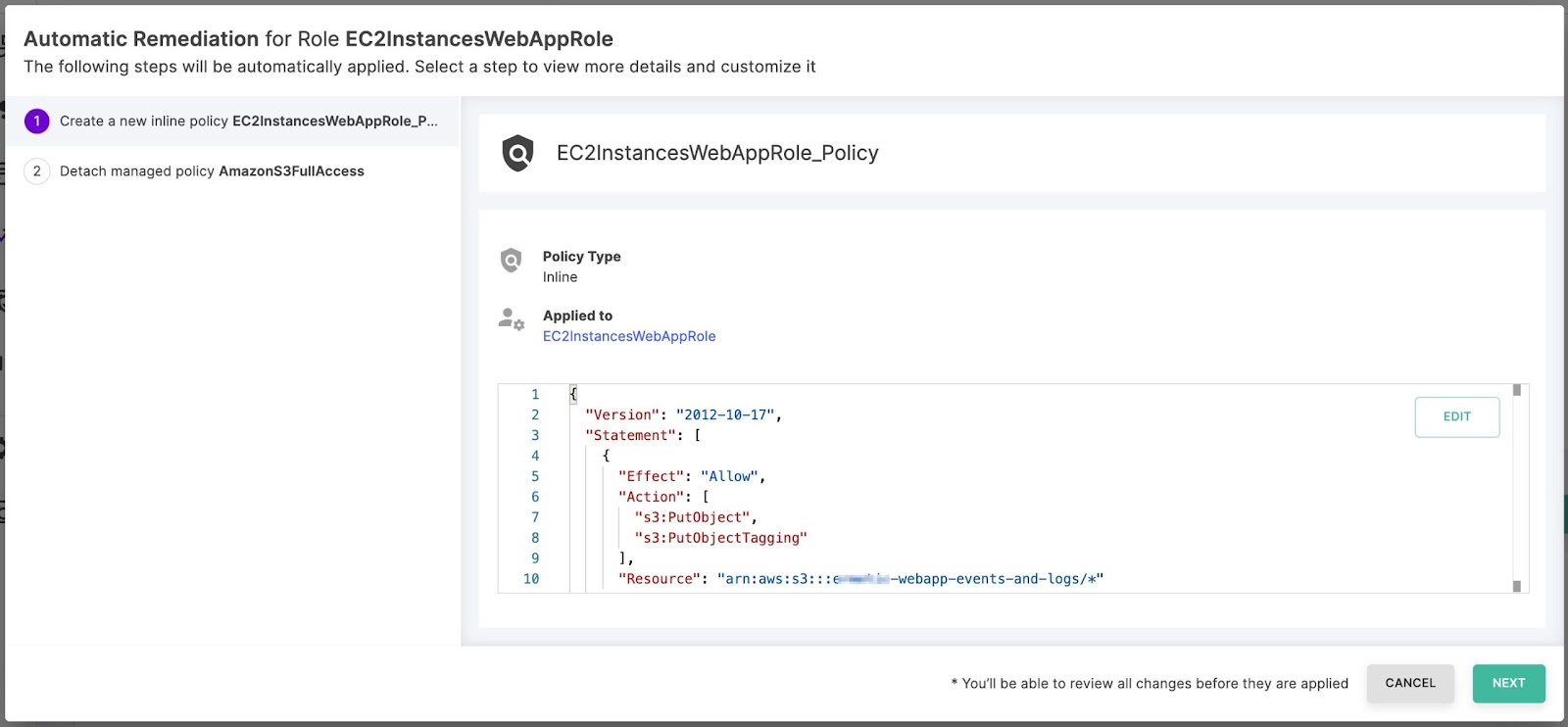
Image source: Tenable
Performing these steps on a regular basis enables you to remove unnecessary AWS managed policies and replace them with strict inline policies.
Where do we go from here?
Even though the managed AWS trap can be lethal, you can avoid it. With Tenable Cloud Security, replace your managed policies with secure, least privilege access policies. If you’re interested in more information, visit our product page and request a demo: https://www.tenable.com/products/tenable-cloud-security
***
Have you heard about Tenable's Access Undenied open-source tool that parses AWS AccessDenied CloudTrail events, explains the reasons for them and offers actionable fixes? Ready to take it for a spin? Try "Access Undenied" here.



Tenable One
Request a demo
The world’s leading AI-powered exposure management platform.
Thank You
Thank you for your interest in Tenable One.
A representative will be in touch soon.
Form ID: 7469
Form Name: one-eval
Form Class: c-form form-panel__global-form c-form--mkto js-mkto-no-css js-form-hanging-label c-form--hide-comments
Form Wrapper ID: one-eval-form-wrapper
Confirmation Class: one-eval-confirmform-modal
Simulate Success